

Haber Afak– DeepSeek’in yanıtlarının büyük ölçüde ChatGPT ile benzer olduğu ortaya çıktı. Yapay zeka modellerinin eğitimi ve fikri mülkiyet hakları konusundaki tartışmalar yeniden gündeme geldi.
Forbes‘un haberine göre, Copyleaks tarafından yürütülen araştırma, farklı yapay zeka modellerinin ürettiği metinlerin analiz edilmesini amaçladı. Çalışmada, GPT, Claude, Gemini, Llama ve DeepSeek gibi modellerin yanıtları incelendi ve DeepSeek’in, ChatGPT’ye %74,2 oranında benzediği tespit edildi.
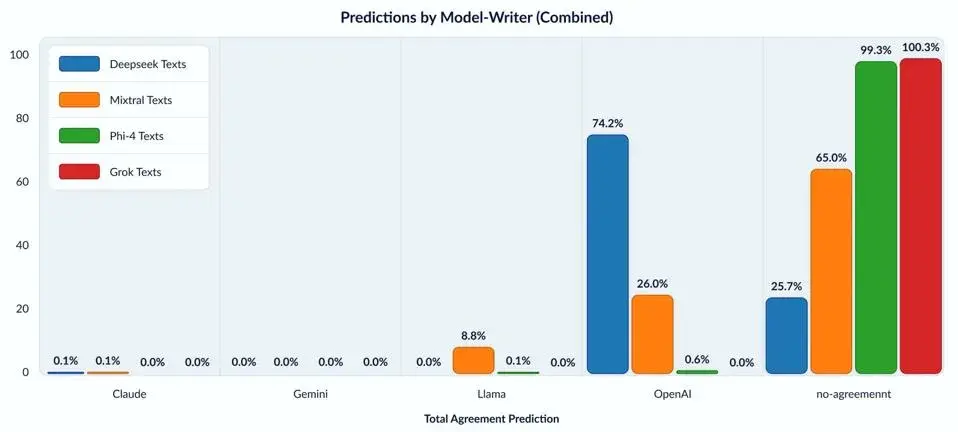
Copyleaks’in Veri Bilimi Başkanı Shay Nissan, araştırmayı el yazısı incelemelerine benzeterek, “Farklı modellerin ürettiği metinleri karşılaştırarak, hangi modelin hangi tarzda yazdığını belirlemeye çalıştık. DeepSeek ve OpenAI modelleri arasında büyük bir benzerlik bulduk. Bu, diğer modellerde gözlemlemediğimiz bir durumdu.” ifadelerini kullandı.
Fikri Mülkiyet Hakları Tartışması
Eğer DeepSeek, OpenAI tarafından üretilen içerikleri izinsiz olarak modelini eğitmek için kullandıysa, bu durum fikri mülkiyet hakları açısından ciddi sonuçlar doğurabilir. Ayrıca, OpenAI’nin hizmet şartlarının ihlal edilmiş olabileceği gündeme gelebilir.

Yapay zeka modellerinin eğitim süreçlerinde kullanılan veri setlerine dair şeffaflık eksikliği, bu tür sorunları daha karmaşık hale getiriyor. Uzmanlar, eğitim veri setlerinin açıklanmasına yönelik daha net düzenlemelere ihtiyaç duyulduğunu vurguluyor.
Karşıt Görüşler de Var
Öte yandan, bazı uzmanlar yapay zeka modellerinin zamanla benzer yanıtlar üretebileceği görüşünü savunuyor. Aynı veya örtüşen veri setleriyle eğitilen modellerin benzer yanıtlar vermesi doğal bir durum olarak değerlendiriliyor.
Ancak Nissan, büyük dil modellerinin farklı veri setleri ve mimari yapılar kullanarak kendilerine özgü bir yazım tarzı geliştirmesi gerektiğini belirtiyor. “Eğer tüm modeller aynı şekilde yanıt veriyorsa, bu bir sorun teşkil eder. Çeşitliliğin korunması ve her modelin kendine has bir karakteristik sunması kritik öneme sahiptir.” diyerek çalışmanın önemine dikkat çekti.















